معظم أدوات الذكاء الاصطناعي التي نستخدمها اليوم تعمل عبر الحوسبة السحابية، مما يعني أنها تتطلب اتصالاً دائمًا بالإنترنت. وعلى الرغم من وجود خيارات لتشغيل أدوات الذكاء الاصطناعي محليًا على أجهزتنا، إلا أن الاعتقاد السائد هو أن ذلك يتطلب عتادًا قويًا ومكلفًا.
هذا ما كنت أظنه أيضًا، إلى أن قررت تجربة تشغيل بعض أدوات الذكاء الاصطناعي المحلية باستخدام جهاز قديم نسبيًا – بطاقة الرسوميات GTX 1070 التي مضى على استخدامها ما يقارب العقد من الزمن – واكتشفت أن الأمر ممكن وفعال بالفعل. هذه التجربة فتحت الباب أمام إمكانيات جديدة لاستخدام الذكاء الاصطناعي حتى على الأجهزة ذات المواصفات المتواضعة، مما يجعل هذه التقنية في متناول شريحة أوسع من المستخدمين.
روابط سريعة
لماذا تحتاج إلى استخدام روبوت دردشة يعمل بالذكاء الاصطناعي محليًا؟
لقد استخدمت عددًا لا يحصى من روبوتات المحادثة التي تعمل بالذكاء الاصطناعي عبر الإنترنت، مثل ChatGPT و Gemini و Claude وغيرها. إنها تعمل بشكل رائع. ولكن ماذا عن تلك الأوقات التي لا يكون لديك فيها اتصال بالإنترنت وما زلت ترغب في استخدام روبوت دردشة يعمل بالذكاء الاصطناعي؟ أو إذا كنت ترغب في العمل على شيء خاص للغاية أو معلومات لا يمكن الكشف عنها للعمل أو غير ذلك؟
هذا هو الوقت الذي تحتاج فيه إلى نموذج لغوي كبير (LLM) محلي وغير متصل بالإنترنت يحتفظ بجميع محادثاتك وبياناتك على جهازك. يسمح لك استخدام روبوت دردشة يعمل بالذكاء الاصطناعي محليًا بالاستفادة من قوة الذكاء الاصطناعي دون الاعتماد على اتصال بالإنترنت.
تعتبر الخصوصية أحد الأسباب الرئيسية لاستخدام نموذج لغوي كبير محلي. ولكن هناك أسباب أخرى أيضًا، مثل تجنب الرقابة والاستخدام دون اتصال بالإنترنت وتوفير التكاليف والتخصيص وما إلى ذلك. يوفر لك روبوت المحادثة المحلي بالذكاء الاصطناعي تحكمًا كاملاً في بياناتك، مما يضمن بقاء معلوماتك الحساسة آمنة ومأمونة.
ما هي نماذج اللغة الكبيرة الكمومية (Quantized LLMs)؟
يمثل العتاد (Hardware) التحدي الأكبر لمعظم الراغبين في استخدام نماذج اللغة الكبيرة (LLM) محليًا. تتطلب النماذج الذكية الاصطناعية الأكثر قوة عتادًا فائق الإمكانات لتشغيلها. وبالإضافة إلى سهولة الاستخدام، تُعد قيود العتاد سببًا آخر لاستخدام معظم روبوتات الدردشة المدعومة بالذكاء الاصطناعي في الحوسبة السحابية.
تُعد قيود العتاد أحد الأسباب التي دفعتني للاعتقاد بأني لن أتمكن من تشغيل نموذج لغة كبير (LLM) محليًا. أمتلك جهاز كمبيوتر متواضعًا هذه الأيام، بمعالج AMD Ryzen 5800x (تم إطلاقه في عام 2020)، وذاكرة وصول عشوائي (RAM) بسعة 32 جيجابايت DDR4، ووحدة معالجة رسوميات GTX 1070 (تم إطلاقها في عام 2016). لذا، فهو ليس قمة العتاد، ولكن بالنظر إلى قلة ممارستي للألعاب هذه الأيام (وعندما أفعل ذلك، أختار ألعابًا مستقلة أقدم وأقل استهلاكًا للموارد) وارتفاع تكلفة وحدات معالجة الرسوميات الحديثة، فأنا سعيد بما لدي.
ومع ذلك، اتضح أنك لست بحاجة إلى أقوى نموذج ذكاء اصطناعي. نماذج اللغة الكبيرة الكمومية (Quantized LLMs) هي نماذج ذكاء اصطناعي تم تصغيرها وتسريعها عن طريق تبسيط البيانات التي تستخدمها، وتحديدًا الأرقام ذات الفاصلة العشرية.
تعمل الذكاء الاصطناعي عادةً بأرقام عالية الدقة (مثل الأرقام ذات الفاصلة العشرية 32 بت)، والتي تستهلك قدرًا كبيرًا من الذاكرة وقوة المعالجة. يقلل التكميم (Quantization) هذه الأرقام إلى أرقام أقل دقة (مثل الأعداد الصحيحة 8 بت) دون تغيير سلوك النموذج كثيرًا. هذا يعني أن النموذج يعمل بشكل أسرع، ويستخدم مساحة تخزين أقل، ويمكن أن يعمل على أجهزة أصغر (مثل الهواتف الذكية أو العتاد الطرفي)، وإن كان ذلك أحيانًا مع انخفاض طفيف في الدقة.


هذا يعني أنه على الرغم من أن العتاد القديم الخاص بي سيواجه صعوبة بالتأكيد في تشغيل نموذج لغة كبير (LLM) قوي مثل نموذج Llama 3.1 ذي 205 مليار معلمة، إلا أنه يمكنه تشغيل النموذج الكمي الأصغر 8B بدلاً من ذلك.
وعندما أعلنت OpenAI عن أول نماذج استدلالية مفتوحة الوزن ومكممة بالكامل، اعتقدت أن الوقت قد حان لمعرفة مدى جودة عملها على العتاد القديم الخاص بي.
كيف أستخدم نموذج لغوي كبير (LLM) محليًا مع بطاقة الرسوميات Nvidia GTX 1070 وبرنامج LM Studio
أود أن أبدأ هذا القسم بالتنويه بأنني لست خبيرًا في النماذج اللغوية الكبيرة المحلية (Local LLMs)، ولا في البرامج التي استخدمتها لتشغيل هذا النموذج الذكي على جهازي. ما سأقدمه هنا هو مجرد شرح لما قمت به لتشغيل روبوت دردشة ذكي يعمل محليًا على بطاقة الرسوميات GTX 1070 الخاصة بي، بالإضافة إلى تقييم لمدى كفاءة هذا الحل. الهدف هو توضيح كيفية الاستفادة من قوة الحوسبة المتاحة لديك لتشغيل نماذج ذكاء اصطناعي متقدمة دون الحاجة إلى الاعتماد على الخدمات السحابية.
تنزيل LM Studio
لتشغيل نموذج لغوي كبير (LLM) محليًا، أنت بحاجة إلى برنامج متخصص. تحديدًا، برنامج LM Studio، وهي أداة مجانية تتيح لك تنزيل وتشغيل نماذج LLM محليًا على جهازك. توجه إلى الصفحة الرئيسية لـ LM Studio واختر Download for [operating system] (أنا أستخدم Windows 10). يعتبر LM Studio منصة مثالية للمطورين والباحثين الذين يرغبون في تجربة النماذج اللغوية الكبيرة المختلفة وتقييم أدائها على أجهزتهم الشخصية قبل نشرها.
إنها عملية تثبيت قياسية لنظام Windows. قم بتشغيل برنامج الإعداد وأكمل عملية التثبيت، ثم قم بتشغيل LM Studio. أنصح باختيار خيار Power User لأنه يكشف عن بعض الخيارات المفيدة التي قد ترغب في استخدامها. يوفر هذا الخيار تحكمًا أكبر في إعدادات البرنامج وخيارات متقدمة لتخصيص تجربة استخدام نماذج LLM. باستخدام LM Studio، يمكنك استكشاف عالم النماذج اللغوية الكبيرة بسهولة وفعالية.
تحميل نموذج الذكاء الاصطناعي المحلي الأول الخاص بك
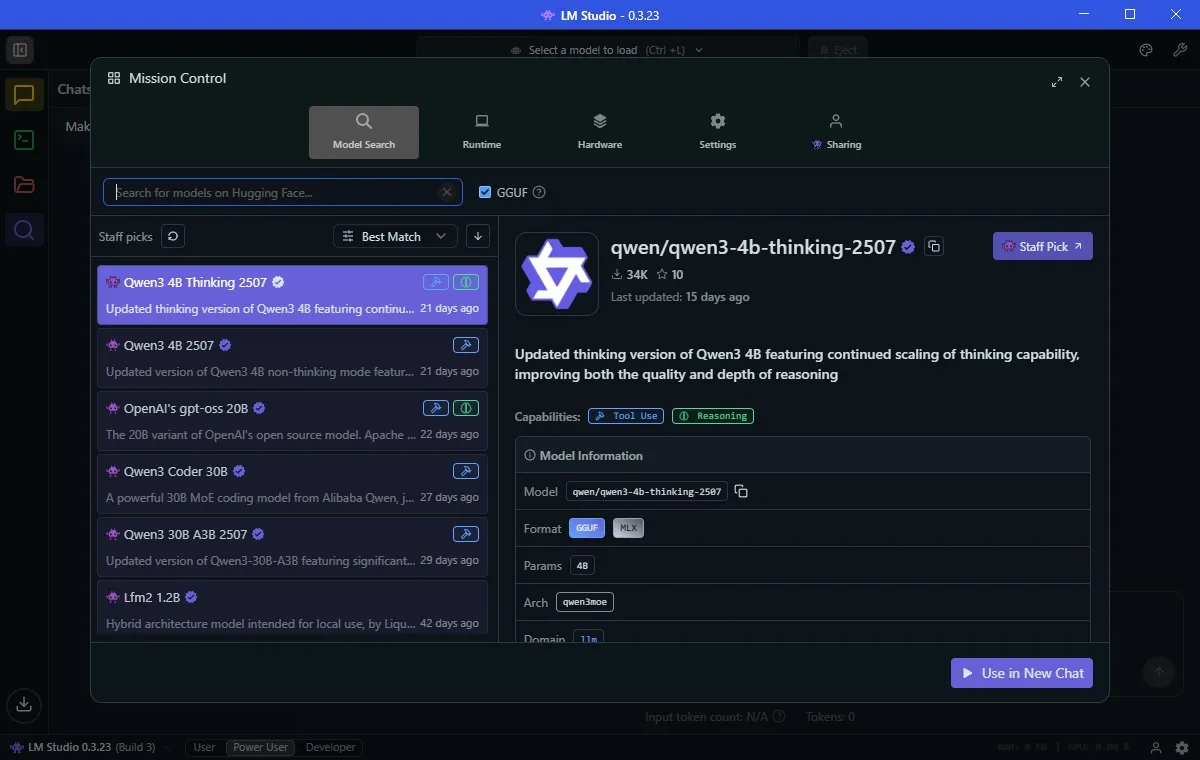
بعد التثبيت، يمكنك تحميل أول نموذج لغوي كبير (LLM). اختر علامة التبويب Discover (أيقونة العدسة المكبرة). يعرض LM Studio بسهولة نماذج الذكاء الاصطناعي المحلية التي ستعمل بشكل أفضل على جهازك.
في حالتي، يقترح تنزيل نموذج باسم Qwen 3-4b-thinking-2507. اسم النموذج هو Qwen (تم تطويره بواسطة عملاق التكنولوجيا الصيني Alibaba)، وهو الإصدار الثالث من هذا النموذج. تعني قيمة “4b” أن هذا النموذج يحتوي على أربعة مليارات معلمة للاستعانة بها للرد عليك، بينما تعني كلمة “thinking” أن هذا النموذج سيقضي وقتًا في التفكير في إجابته قبل الرد. أخيرًا، 2507 هو آخر مرة تم فيها تحديث هذا النموذج، في 25 يوليو.
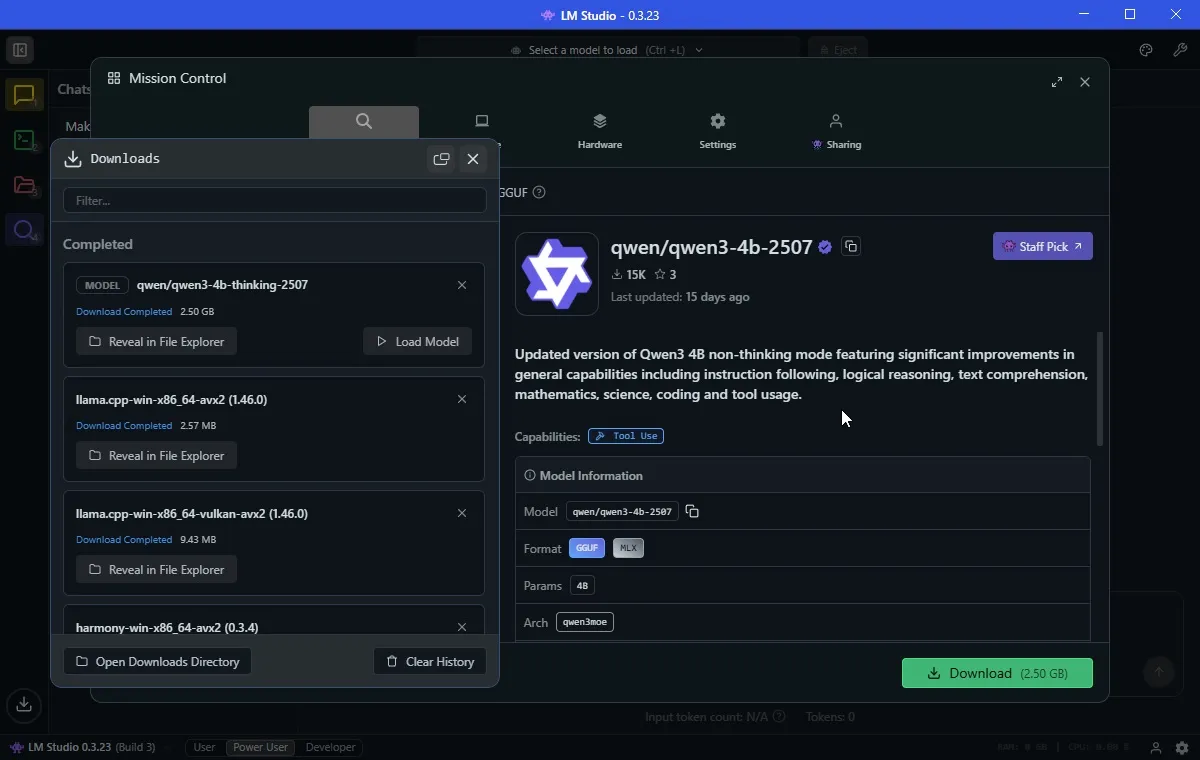
حجم Qwen3-4b-thinking هو 2.5 جيجابايت فقط، لذلك لن يستغرق تنزيله وقتًا طويلاً. لقد قمت أيضًا بتنزيل OpenAI/gpt-oss-20b مسبقًا، وهو أكبر حجمًا حيث يبلغ 12.11 جيجابايت. كما أنه يتميز بـ 20 مليار معلمة، لذلك يجب أن يقدم إجابات “أفضل”، على الرغم من أنه سيأتي بتكلفة موارد أعلى.
الآن، وبصرف النظر عن تعقيدات أسماء نماذج الذكاء الاصطناعي، بمجرد تنزيل LLM، تكون جاهزًا تقريبًا لبدء استخدامه.
قبل تشغيل نموذج الذكاء الاصطناعي، انتقل إلى علامة التبويب Hardware وتأكد من أن LM Studio يحدد نظامك بشكل صحيح. يمكنك أيضًا التمرير لأسفل وضبط Guardrails هنا. لقد قمت بتعيين الحواجز الواقية على جهاز الكمبيوتر الخاص بي على Balanced، مما يمنع أي نموذج ذكاء اصطناعي من استهلاك الكثير من الموارد، مما قد يتسبب في زيادة تحميل النظام.
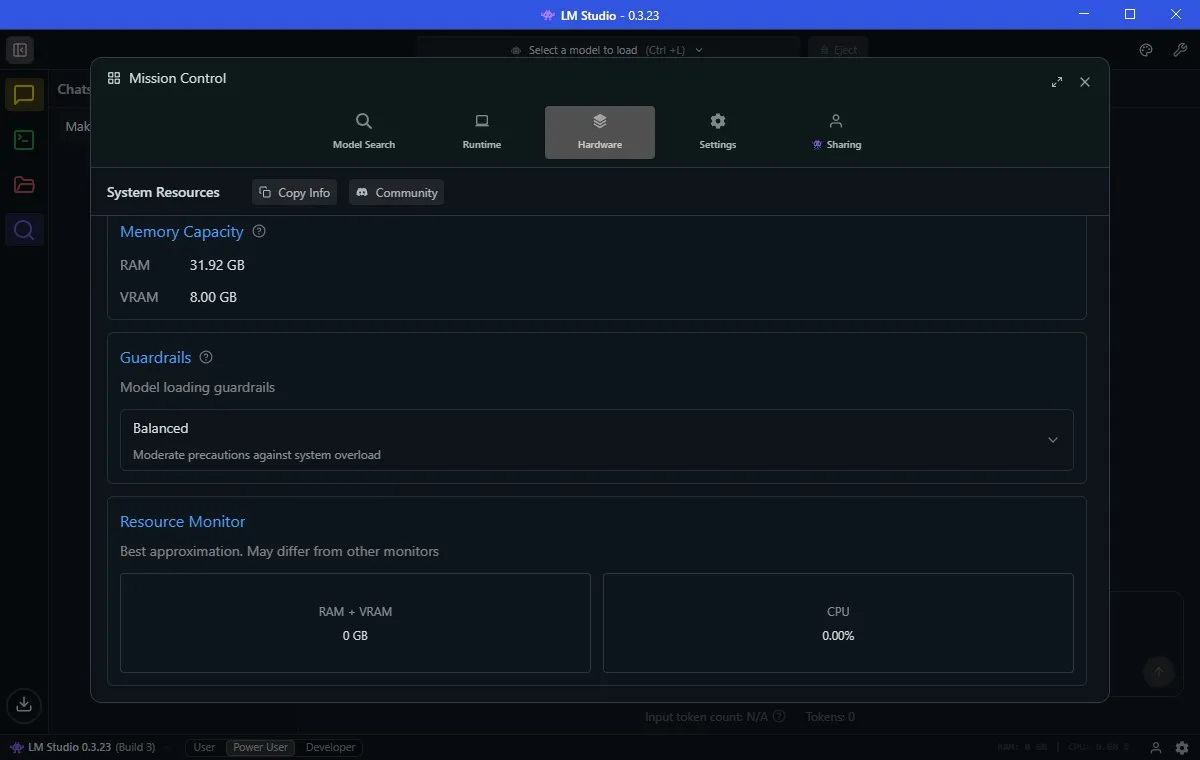
ستلاحظ أيضًا Resource Monitor أسفل Guardrails. هذه طريقة سهلة لمعرفة مقدار النظام الذي يستهلكه نموذج الذكاء الاصطناعي. يجدر مراقبته إذا كنت تستخدم أجهزة محدودة إلى حد ما مثلي، لأنك لا تريد أن يتعطل نظامك بشكل غير متوقع.
تحميل نموذج الذكاء الاصطناعي الخاص بك والبدء في استخدامه
أنت الآن على استعداد تام للبدء في استخدام روبوت دردشة يعمل بتقنية الذكاء الاصطناعي محليًا على جهازك. في برنامج LM Studio، حدد الشريط العلوي، الذي يعمل كأداة بحث. سيؤدي تحديد اسم الذكاء الاصطناعي إلى تحميل نموذج الذكاء الاصطناعي في ذاكرة جهاز الكمبيوتر الخاص بك، ويمكنك البدء في إدخال الأوامر والأسئلة. هذه العملية ضرورية لتفعيل قدرات النموذج اللغوي الكبير (LLM) على جهازك مباشرة، مما يتيح لك تجربة تفاعلية وسريعة مع الذكاء الاصطناعي دون الحاجة إلى اتصال دائم بالإنترنت. تذكر أن أداء النموذج يعتمد على مواصفات جهازك، لذا تأكد من أن لديك موارد كافية لتشغيل نموذج الذكاء الاصطناعي بكفاءة.
تشغيل نموذج ذكاء اصطناعي محليًا على أجهزة قديمة: رائع، ولكن مع قيود
يتيح لك تشغيل نموذج الذكاء الاصطناعي محليًا الاستفادة منه بالطريقة المعتادة، ولكن يجب أن تكون على دراية ببعض القيود الهامة. هذه النماذج المحلية، على الرغم من فائدتها، لا تضاهي قوة النماذج المتطورة مثل GPT-5 المستخدمة في ChatGPT. بالإضافة إلى ذلك، ستلاحظ أن عملية التفكير والاستجابة تستغرق وقتًا أطول بكثير، وقد تختلف جودة الاستجابات بشكل ملحوظ.
لتوضيح ذلك، قمت بتجربة اختبار نموذج لغوي كبير (LLM) كلاسيكي على كل من Qwen و gpt-oss، وقد نجح كلاهما في إكمال المهمة، ولكن بعد فترة انتظار طويلة. هذا يوضح أن استخدام نموذج ذكاء اصطناعي محليًا على جهاز قديم يمكن أن يكون حلاً عمليًا، ولكنه يتطلب صبرًا وفهمًا لحدود قدرات الأجهزة القديمة.
ألن وبوب وكولين وديف وإيميلي يقفون في دائرة. ألن على يسار بوب مباشرة. بوب على يسار كولين مباشرة. كولين على يسار ديف مباشرة. ديف على يسار إيميلي مباشرة. من على يمين ألن مباشرة؟
استغرق Qwen 5 دقائق و11 ثانية للوصول إلى الاستنتاج الصحيح. استغرق GPT-5 حوالي 45 ثانية فقط. ولكن من الذي تفوق على الجميع؟ gpt-oss-20b بزمن قياسي قدره 31 ثانية.
اختبار واحد ليس كافيًا، لذلك قمت بتجربته على لغز آخر مصمم لاختبار مهارات الاستدلال لدى الذكاء الاصطناعي. في اختبار سابق، فشل أحدث نموذج من OpenAI، وهو GPT-5، في هذا الاختبار، لذلك كنت حريصًا على معرفة كيف ستتعامل النسخ غير المتصلة بالإنترنت من Qwen و gpt-oss معها.
تحليل أداء نماذج الذكاء الاصطناعي في حل المشكلات المنطقية
تعتبر القدرة على حل المشكلات المنطقية تحديًا حقيقيًا لنماذج الذكاء الاصطناعي. يوضح المثال أعلاه، الذي يتضمن تحديد العلاقات المكانية بين مجموعة من الأشخاص، مدى تفاوت أداء هذه النماذج.
العلاقات المكانية وتحديات الذكاء الاصطناعي
تعتبر معالجة العلاقات المكانية جزءًا أساسيًا من الذكاء الاصطناعي، حيث تتطلب فهمًا دقيقًا للغة وقدرة على الاستنتاج المنطقي. يتضح من خلال المثال السابق أن بعض النماذج، مثل gpt-oss-20b، تتفوق في هذا المجال، بينما تحتاج نماذج أخرى، مثل Qwen و GPT-5، إلى وقت أطول للوصول إلى الحل الصحيح.
أهمية الاختبارات المتنوعة لتقييم الذكاء الاصطناعي
لا يمكن الاعتماد على اختبار واحد فقط لتقييم قدرات الذكاء الاصطناعي بشكل شامل. من الضروري إجراء مجموعة متنوعة من الاختبارات التي تغطي جوانب مختلفة من الذكاء، مثل الاستدلال المنطقي، وفهم اللغة، وحل المشكلات المعقدة. هذا يسمح بتقييم أكثر دقة لقدرات ومحدوديات كل نموذج.
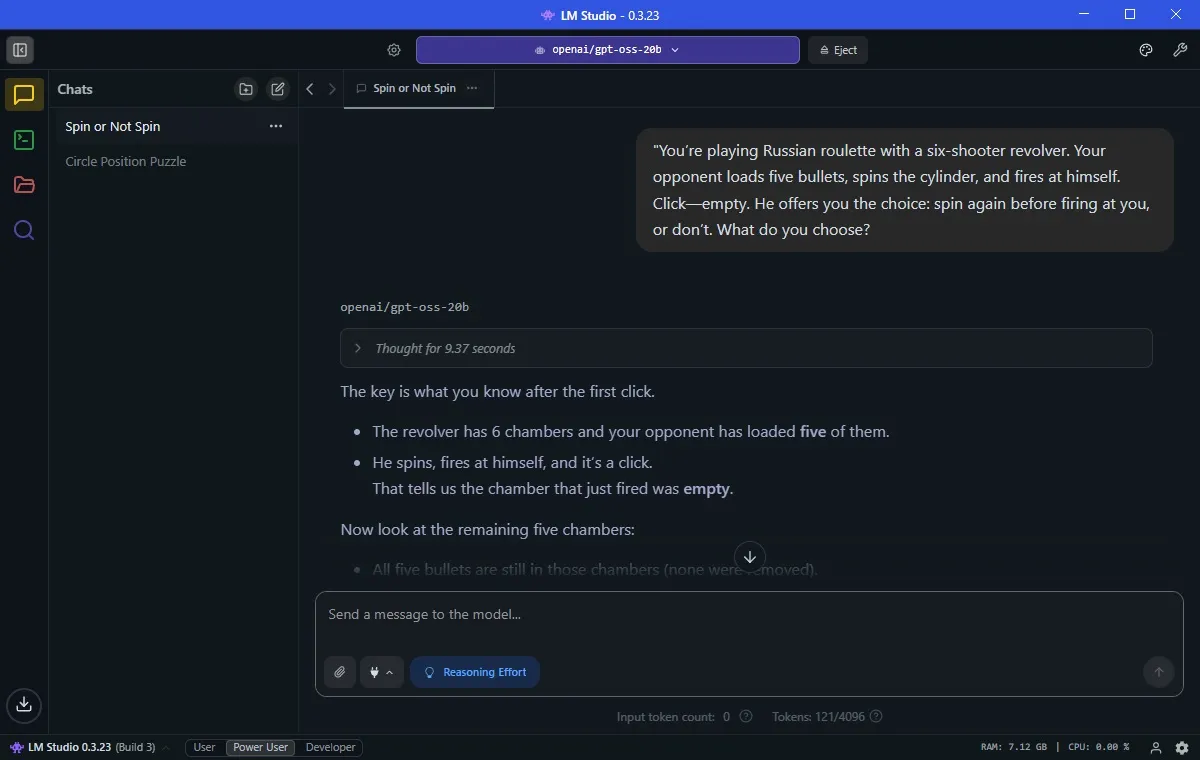
تخيل أنك تلعب لعبة الروليت الروسية بمسدس بستة طلقات. يقوم خصمك بتعبئة خمس رصاصات، وتدوير الأسطوانة، ثم يطلق النار على نفسه. “تكة” – فارغة. ثم يعرض عليك الاختيار: هل تريد تدوير الأسطوانة مرة أخرى قبل أن يطلق النار عليك، أم لا؟ ماذا تختار؟
لقد تمكن نموذج Qwen من إعطاء الإجابة الصحيحة في دقيقة و41 ثانية، وهو وقت جيد جدًا (مع الأخذ في الاعتبار القيود المتعلقة بالأجهزة). ولكن المثير للدهشة أن GPT-5 فشل في حل هذه المشكلة، وهو أمر مفاجئ حقًا. بل وعرض أن يقدم لي مخططًا يوضح لماذا كان على حق. ومرة أخرى، حصل gpt-oss-20b على الإجابة الصحيحة في 9 ثوانٍ فقط.
في مجالات أخرى، رأيت أيضًا نجاحًا فوريًا. طلبت من gpt-oss أن “يكتب لي لعبة الثعبان باستخدام pygame”، وفي غضون دقيقة أو دقيقتين، كانت لدي لعبة الثعبان تعمل بكامل طاقتها. هذا يوضح قدرة النموذج على إنشاء الألعاب بكفاءة.

تشغيل نموذج ذكاء اصطناعي على أجهزتك القديمة
يكمن جوهر تشغيل نموذج لغوي كبير (LLM) محليًا على الأجهزة القديمة في اختيار نموذج الذكاء الاصطناعي المناسب لإمكانيات جهازك. في حين أن إصدار Qwen قد عمل بشكل جيد وكان الخيار الأفضل في LM Studio، إلا أنه من الواضح أن نموذج gpt-oss-20b من OpenAI هو الخيار الأفضل بكثير.
لكن من الضروري أن توازن توقعاتك. على الرغم من أن gpt-oss أجاب على الأسئلة بدقة (وبسرعة أكبر من GPT-5)، إلا أنني لن أتمكن من إلقاء كمية هائلة من البيانات لمعالجتها. ستظهر قيود أجهزتي بسرعة.
قبل أن أجرب، كنت مقتنعًا بأن تشغيل روبوت دردشة ذكاء اصطناعي محلي على أجهزتي القديمة كان مستحيلاً. ولكن بفضل النماذج الكمية وأدوات مثل LM Studio، لم يعد ذلك ممكنًا فحسب، بل إنه مفيد بشكل مدهش.
ومع ذلك، لن تحصل على نفس السرعة أو الدقة أو عمق التفكير الذي تحصل عليه من شيء مثل GPT-5 في السحابة. يتضمن التشغيل محليًا مفاضلات: تكسب الخصوصية والوصول دون اتصال بالإنترنت والتحكم في بياناتك، ولكنك تتخلى عن بعض الأداء.
ومع ذلك، فإن حقيقة أن وحدة معالجة الرسومات (GPU) عمرها سبع سنوات ووحدة معالجة مركزية (CPU) عمرها أربع سنوات يمكنها التعامل مع الذكاء الاصطناعي الحديث على الإطلاق أمر مثير للغاية. إذا كنت مترددًا لأنك لا تمتلك أجهزة متطورة، فلا تتردد – فقد تكون النماذج المحلية الكمية هي طريقك إلى عالم الذكاء الاصطناعي دون اتصال بالإنترنت. استخدم نموذج الذكاء الاصطناعي المناسب لتحقيق أقصى استفادة من أجهزتك القديمة.